
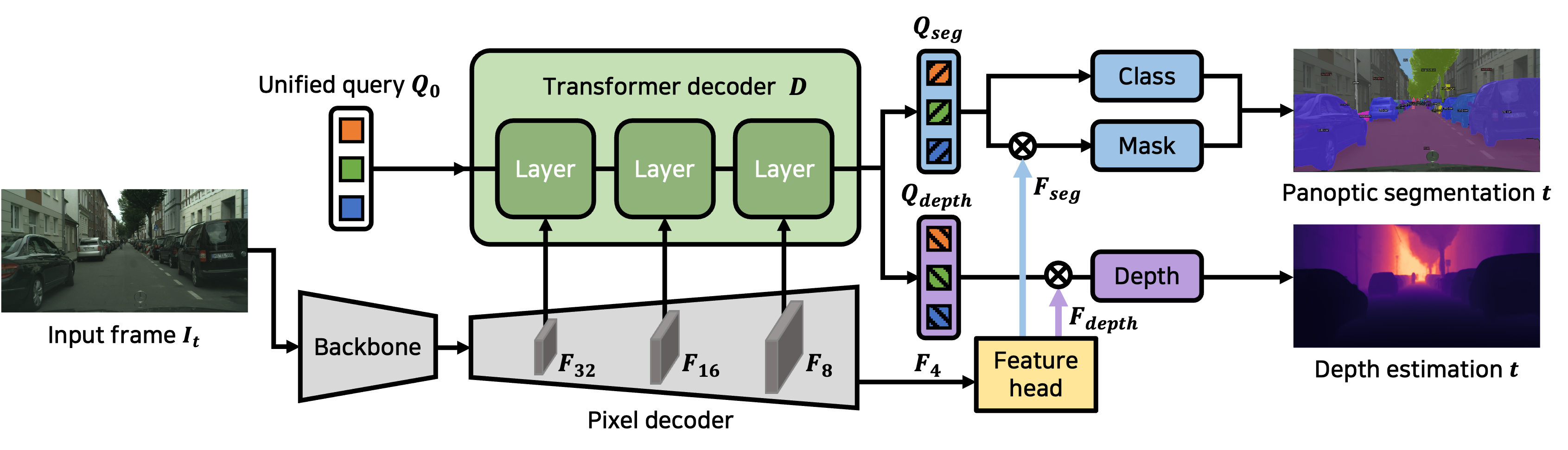
We present Uni-DVPS, a unified model for Depth-aware Video Panoptic Segmentation (DVPS) that jointly tackles distinct vision tasks, i.e., video panoptic segmentation, monocular depth estimation, and object tracking. In contrast to the prior works that adopt diverged decoder networks tailored for each task, we propose an architecture with a unified Transformer decoder network.
We design a single Transformer decoder network for multi-task learning to increase shared operations to facilitate the synergies between tasks and exhibit high efficiency. We also observe that our unified query learns instance-aware representation guided by multi-task supervision, which encourages query-based tracking and obviates the need for training extra tracking module.
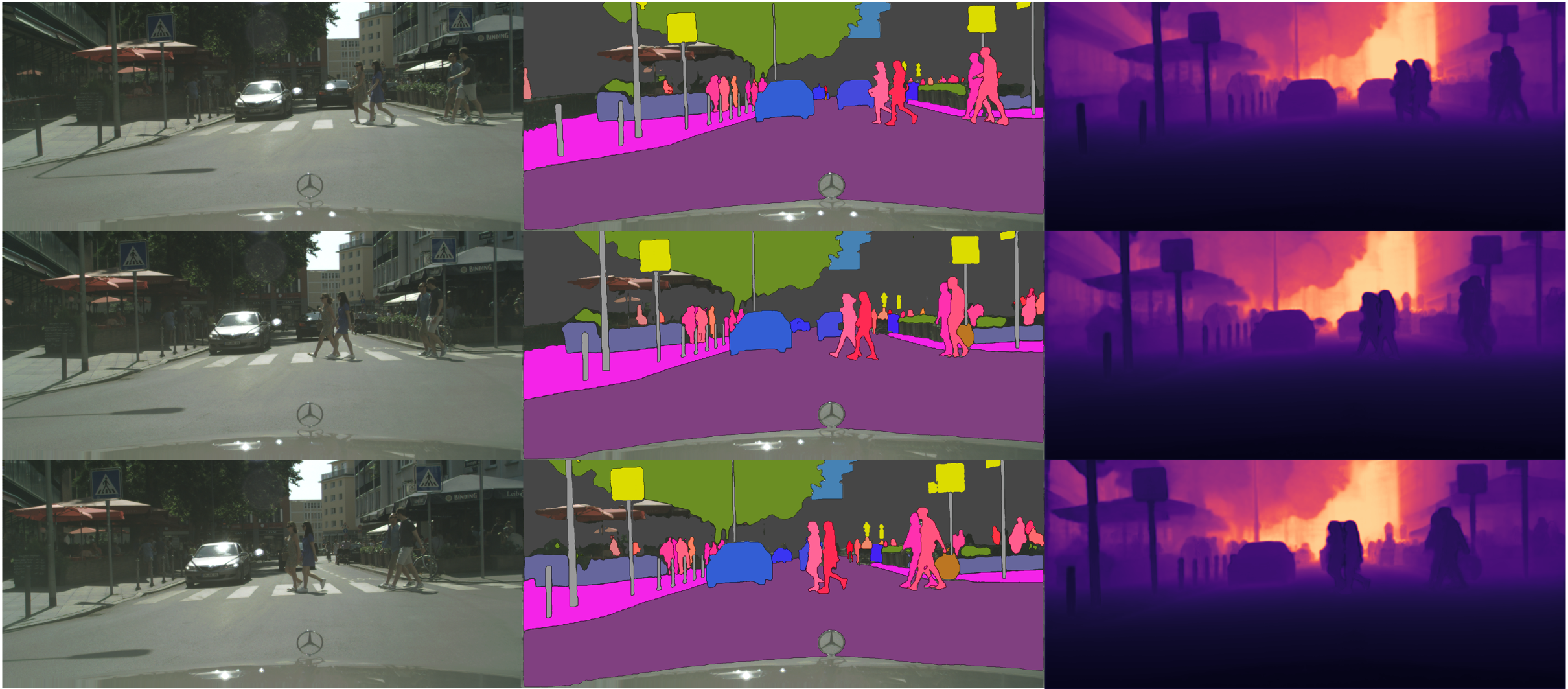
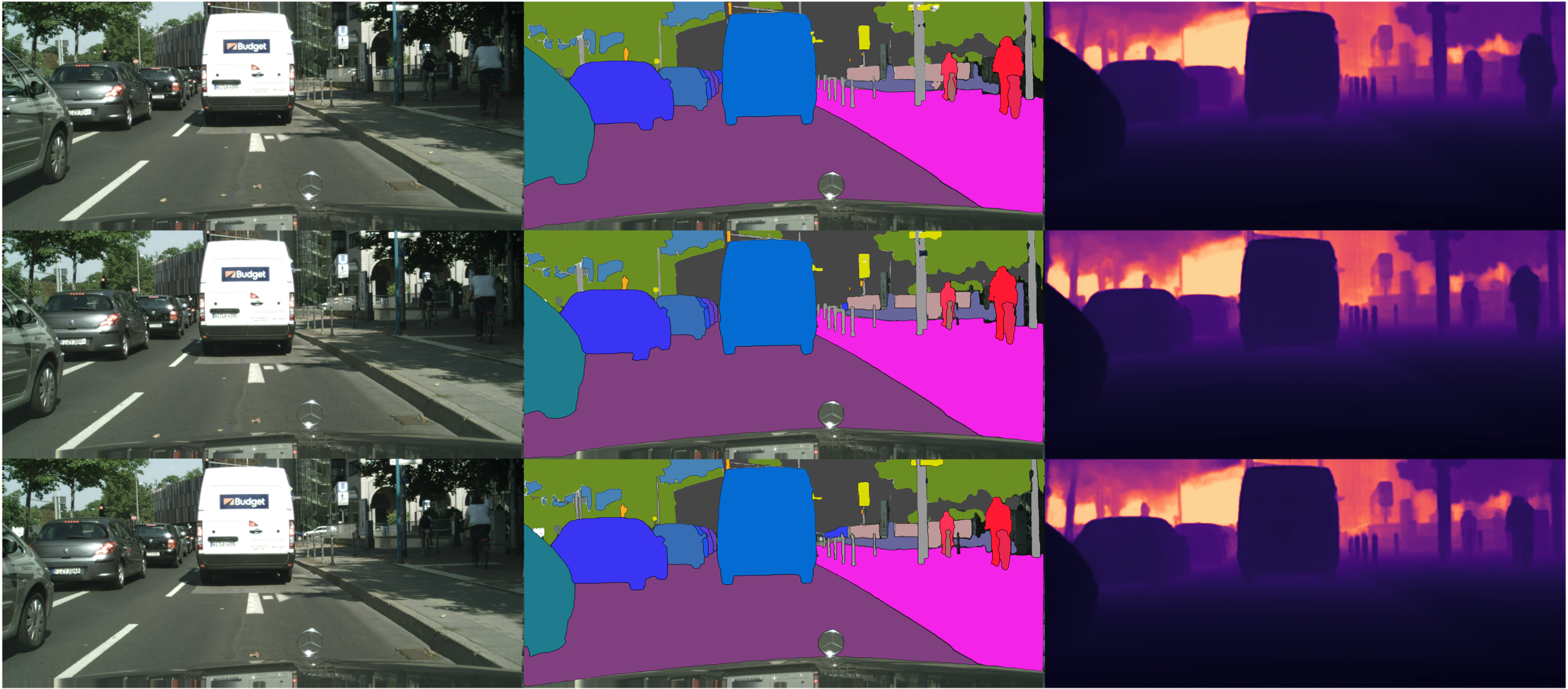
We validate our architectural design choices with experiments on Cityscapes-DVPS and SemKITTI-DVPS datasets. The performances of all tasks are jointly improved, and we achieve state-of-the-art results on DVPQ metric for both datasets.

@article{jiyeon2024unidvps,
title={Uni-DVPS: Unified Model for Depth-Aware Video Panoptic Segmentation},
author={Ji-Yeon, Kim and Hyun-Bin, Oh and Byung-Ki, Kwon and Kim, Dahun and Kwon, Yongjin and Oh, Tae-Hyun},
journal={IEEE Robotics and Automation Letters},
year={2024},
publisher={IEEE}}